Table of contents
Author


User Authentication: Comparing Session-based and Token-based Implementations
These days, it’s almost impossible to find a web application that doesn’t use some form of user authentication. End users must typically go through a login process to access an app’s full features and protected resources.
But how user authentication is implemented varies depending on the application's specific requirements and type.This holds true for both traditional username and password authentication as well as the one implemented via a federated authentication protocol, such as OpenID Connect.
In this blog post, we’ll provide an overview of session-based and token-based implementation methods used in traditional authentication. We will highlight the differences between user sessions and tokens for maintaining authentication state and show how they cater for different application architectures.
Additionally, we’ll cover the two primary authentication flows defined by OpenID Connect: the Authorization Code Flow and the Proof Key for Code Exchange (PKCE) Flow. We’ll discuss how to select the right flow according to the application type and incorporate the user information received from OpenID Provider into an existing authentication logic, either session- or token-based.
The main goal is to identify key factors to consider when choosing between session-based and token-based authentication. We’ll also explore how OpenID Connect flows can be efficiently integrated into an application with authentication mechanisms already in place.
1. Authentication with user credentials
User credentials are a common way for web applications to verify user identity. With this method, users provide a unique combination of a username and password to gain access to protected resources and data within the application. The authentication process involves validating the provided credentials against user data stored in the application’s database.
From registration to authentication: a mechanism for storing the user’s authentication state
Let’s consider what happens when a new, unregistered user interacts with an application for the first time.
Upon this first interaction, the user will go through a registration process and enter their username and password on the application’s registration page. Once the user submits their credentials, this information is sent to the server and stored in the application's database. This is typically done via an API endpoint or server-side code that handles the user registration process.
The next time the registered user requests to access a protected resource within the application, they’ll have to prove they have the necessary access rights. To avoid asking the user for login credentials on every request, it’s necessary to implement a mechanism for storing the user’s authentication state across multiple HTTP requests. This is due to the stateless nature of HTTP protocol, where each request is processed independently and doesn’t have access to information from previous requests.
The two mechanisms commonly used for this purpose are user sessions and bearer tokens. Developers will choose between the two (or implement a combination of both) based on the type of application they’re working with, security and usability considerations, and personal preferences.
User sessions and cookies
The term “user session” refers to a series of user interactions with the application in a given timeframe. A session contains information about authenticated users and typically includes a unique session ID, login and expiration times, and other relevant data.
Sessions are generated and stored on the server, allowing the server to keep track of and authorize the user’s requests. After creating a session, the server sets a cookie that contains the session ID and sends it to the browser. Once the cookie is stored, the browser will include it in all further requests until it expires or the user logs out. The server will use the cookie to identify the current user session.
User sessions and cookies have been around for a long time and are still extensively used, especially in traditional web applications where authentication is often implemented on the server side.
Bearer tokens
Another common mechanism for managing user authentication is the use of bearer tokens. While other token formats exist, JSON Web Tokens (JWTs) have become the prevailing standard for token-based authentication.
A “token” is a cryptographically signed piece of data that contains information about the authenticated user and their access permissions. When a user logs in, the server creates a bearer token and sends it to the client. The client then saves the token and includes it in each subsequent request it sends to the server. Unlike with a user session, the server will only have to verify the validity of the token rather than having it stored in a database. This is possible because the token itself contains all the information needed to prove its validity.
With token-based authentication, the server isn’t required to store each user’s authentication status, which ultimately reduces the amount of state that needs to be stored on the server.
Bearer tokens are a popular choice for modern Single-Page Applications (SPAs) where authentication is often done on the client side and where speed, user experience, and scalability are often prioritized.
With this understanding of sessions and tokens, we can move on to creating a more complete picture of session-based and token-based authentication flows.
Session-based authentication
Session-based authentication operates in a stateful manner. This means that a session record must be kept on both the server and the client side. The server will keep track of active user sessions and store them in memory or in a database, and the browser will have the session ID in a cookie.
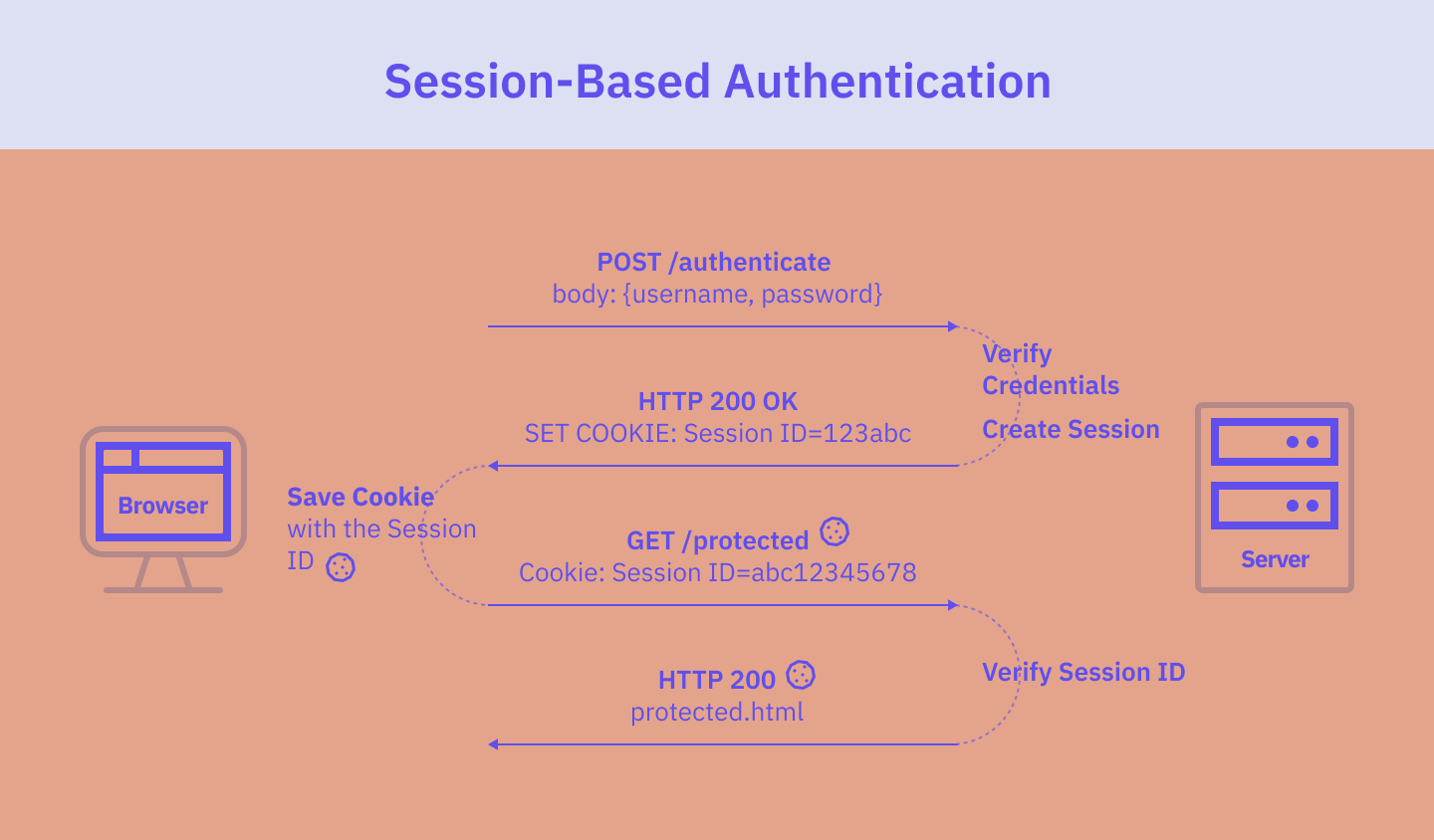
The flow of the session-based authentication is as follows:
- The user enters their credentials into the application’s login form. Once the form is submitted, the browser sends to the server a POST request with the form input.
- The server verifies the user's credentials, by e.g. checking them against a database of authorized users. If the credentials match, the server creates a user session with a unique session ID and stores it in a database.
- The server then returns the session ID to the browser, usually by including a Set-Cookie header in the response containing a cookie with the session ID.
- The cookie with the session ID is stored in the browser.
- From now on, every time this user requests a page, the browser will include a cookie with the session ID in every request sent to the server.
- The server receives the request and checks the session ID.
- If the session ID is valid, the server responds with the requested resource.
- Once the user logs out, the session is destroyed on the server, and the session cookie is deleted from the browser.
Session-based authentication is still commonly used and has its advantages. It works really well in a traditional server/browser model but may not be ideal for modern web applications that require frequent data exchanges between the client and the server.
Token-based authentication
With the rise of Single-Page Applications and APIs, token-based authentication has become increasingly popular. This approach relies on the use of tokens for user authentication and operates in a stateless manner. Unlike session-based authentication, token-based authentication eliminates the need for the server to keep track of the issued tokens or logged-in users. Instead, the server only checks the validity of the tokens it receives.
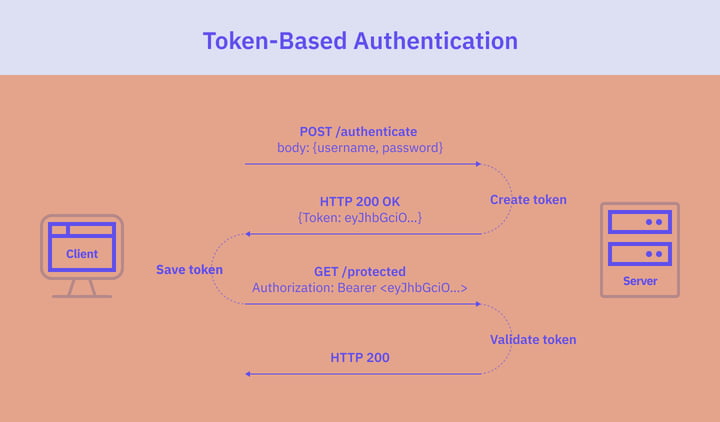
The authentication flow of token-based authentication is as follows:
- The user enters their credentials into the application’s login form. The client sends the user's credentials to the server in a POST request.
- The server verifies the user's credentials by checking them against a database and generates a bearer token. The bearer token contains information such as the user's identity and any relevant permissions or roles.
- The server sends the token back to the client.
- The client receives the token and stores it locally for use in subsequent requests to protected resources. In browser-based applications, the token is usually stored in the localStorage or sessionStorage. In native mobile applications, it’s stored in the appropriate storage offered by the OS.
- The client sends the token along with each subsequent request to the server, usually in the Authorization header of the HTTP request:
Authorization: Bearer <token> - The server checks the validity and authorization of the token on each request.
- If the token is valid, the server authorizes the request.
- Once a user logs out, the token is destroyed on the client side. No interaction with the server is required.
Token-based authentication has several advantages, including a smoother user experience, reduced server workload, and better scalability and performance due to its stateless nature. However, it introduces some security concerns related to the use of tokens, given the sensitive data they hold.
Choosing the right approach
The use of sessions vs. tokens in user authentication is a widely debated topic.
Some developers prefer server-side sessions and cookies: a reliable method that fits well into the still widespread traditional web applications architecture. Others opt for tokens, as they can offer improved user experience, help avoid the complexity around cross-domain cookies, and work great in modern SPAs and mobile applications.
For an exhaustive summary of benefits and considerations when choosing between session- and token-based authentication, this article is a great resource.
Another viable approach is a combination of both server-side sessions and tokens. For instance, a user could be authenticated via a bearer token on the client side, while the server verifies the user's authentication state with a server-side session.
All things considered, there are no universal rules when it comes to selecting the most appropriate authentication implementation. The choice will largely depend on the specific needs and requirements of each application and the application architecture. If implemented with the best security practices and usability requirements in mind, both sessions and tokens (or their combination) can deliver sufficient levels of protection and a user-friendly authentication mechanism.
2. Authentication with OpenID Connect
The federated identity model offers a compelling alternative to traditional username and password authentication.
By leveraging a federated authentication protocol, such as OpenID Connect (OIDC), developers can streamline the authentication process and provide users with a familiar and convenient way to access applications by logging in with an external identity provider. For instance, users can log in with their existing Google or Facebook accounts, or with national eIDs.
OpenID Connect: choosing between Authorization Code Flow and PKCE
OpenID Connect defines several authentication flows that outline how the client application should interact with an OpenID Provider.
Let’s compare the two OIDC flows widely used and recommended for user authentication: the Authorization Code Flow and the Proof Key for Code Exchange (PKCE) flow.
Both of them involve users sharing their credentials with an OpenID Provider. In both cases, the OpenID Provider issues a token that represents the user. However, the two flows are designed to work best in different application types.
The Authorization Code Flow is intended for traditional web applications that have a server-side component and can securely store a client secret. This flow involves exchanging the authorization code obtained from the OpenID Provider for a token. To perform the code-for-token exchange, the client application presents the authorization code along with a client secret to request a token. The client secret is a confidential identifier known only to the client application and the OpenID Provider.
The PKCE Flow (or Authorization Code Flow + PKCE) is an extension of the Authorization Code Flow and also requires the code-for-token exchange. But in place of a client secret, the PKCE Flow introduces a code verifier (a one-time secret created by the client application that can be verified by the OpenID Provider) and a code challenge (a hashed and encoded version of the code verifier). During the code-for-token exchange, the client application presents the authorization code along with the code verifier. The OpenID Provider will only proceed with the token exchange if this code verifier matches the original code challenge created by the client application. The combination of the code challenge and code verifier in PKCE Flow ensures that even if the authorization code is intercepted during transmission, it cannot be exchanged for a token by an unauthorized party.
The PKCE Flow was specifically designed to authenticate native or mobile application users. It is considered best practice in native and Single-Page Applications that don’t have a way to securely store a client secret. PKCE Flow can also be a good choice for other types of applications because it can create a smoother user experience in certain situations. For example, in applications that have an SPA client connected to a server, the PKCE Flow works best because the authentication process is resolved on the client side.
Now that we have explored how the two OIDC authentication flows are best suited for different application architectures, let’s discuss their integration into a client application that already has authentication logic in place.
In short: For session-based authentication, we recommend using the Authorization Code Flow. This flow aligns well with traditional web application architecture and provides a high level of security if the application has a server-side component capable of securely storing a client secret.
The PKCE Flow, on the other hand, is a logical choice for the client-side token-based authentication model, often implemented by native applications or SPAs. The PKCE Flow provides additional security for applications that either don’t have a secure way to keep a client secret or have specific requirements related to the user experience.
The short table below offers a summary:
|
Session-Based Authentication |
Token-Based Authentication |
Hybrid Approach Combining Sessions and Tokens |
|
Authorization Code Flow |
PKCE Flow recommended |
PKCE Flow most likely, but possible to use both |
Connecting the JWT output to a bearer token or user session
Once the OIDC flow completes and the client application receives the JWT token from the OpenID Provider, it can either use the token directly or extract and use the information contained in the JWT claims. The way in which the client application implements authentication determines how the JWT output is handled.
Session-based authentication and OIDC
As discussed, session-based authentication involves generating a unique session ID within the application and storing it in a database.
When leveraging the user information obtained through OIDC authorization, one option is to store the JWT in the user session. Alternatively, you can extract specific information from the JWT and link it to the session for future reference.
In either case, the session ID will then be used to associate subsequent requests from the same user with their stored session information.
Token-based authentication and OIDC
With token-based authentication, you can either use the JWT issued by the OpenID Provider as your own bearer token or have your backend generate a new bearer token based on the JWT received from OIDC authentication. The first option is the most common choice, but there are some situations where generating a new bearer token is more suitable. For instance:
- If your client application already relies on a specific bearer token format for its existing authentication logic, deriving a new bearer token can help ensure compatibility.
- Similarly, if your application interacts with external services and APIs that have specific requirements for the token format, you need to issue a new bearer token that aligns with these.
- Issuing a new bearer token offers more flexibility, allowing you to customize the token according to your application’s needs (e.g. by including additional claims or metadata).
- Generating a new bearer token gives you more control over the token lifecycle and may be necessary if you have specific requirements for token expiration and revocation.
Summary
When implementing user authentication, developers have the option to choose between sessions-based and token-based approaches.
Server-side sessions and cookies offer robust security and control over session state and are a great option for traditional web applications. On the other hand, bearer tokens can provide an improved user experience and work very well in modern SPAs and mobile applications. There are also hybrid approaches that combine server-side state and tokens to leverage the strengths and mitigate problems inherent to both methods.
Ultimately, the best approach for implementing authentication will largely depend on specific requirements, security considerations, and the application architecture type. There is no single solution that works equally well for every case.
The application type along with security and usability considerations will also play a defining role when choosing the most suitable OpenID Connect flow. Traditional web applications with a server-side component can safely leverage the Authorization Code Flow. But native applications and pure SPAs shouldn’t use Authorization Code Flow without adding the Proof Key of Code Exchange. For these applications, PKCE Flow is the more secure, recommended option. PKCE can also be beneficial in other types of application architectures, such as server-based applications with SPA clients.
When OpenID Connect is incorporated into a client application with existing authentication logic, we recommend using the Authorization Code Flow with a session-based model and the PKCE Flow with the token-based model.
While there is much more to explore, we hope this post will help you make an informed decision when implementing authentication mechanisms into your application.
Happy Coding!
Author


